Regex or regular expression is a pattern-matching tool. It allows you to search text in an advanced manner.
Regex is like CTRL+F on steroids.
For example, to find out all the emails or phone numbers from text, regex can get the job done.
The downside of the regex is it takes a while to memorize all the commands. One could say it takes 20 minutes to learn, but forever to master.
In this guide, you learn the basics of regex.
We are going to use the regex online playground in regexr.com. This is a super useful platform where you can easily practice your regex skills with useful examples.
Make sure to write down each regular expression you see in this guide to truly learn what you are doing.
Regex Tutorial
To make it as beneficial as possible, this tutorial is example-heavy. This means some of the regex concepts are introduced as part of the examples. Make sure you read everything!
Anyway, let’s get started with regex.
Regex and Flags
A regular expression (or regex) starts with forward slash (/) and ends with a forward slash.
The pattern matching happens in between the forward slashes.
For instance, let’s find the word “loud” in the text document.

As you can see, this works like CTRL + F.
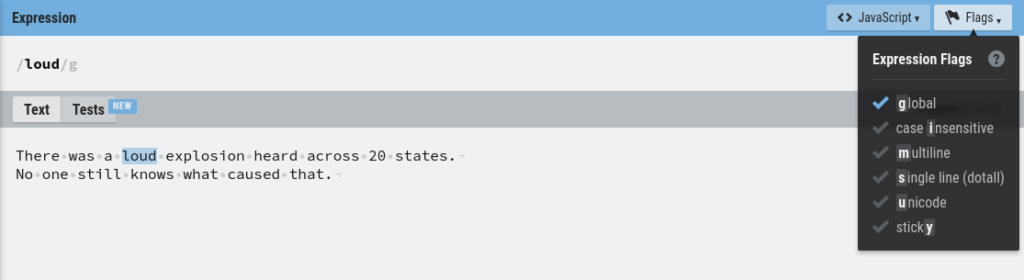
Next, pay attention to the letter “g” in the above regex /loud/g.
The letter “g” means that the global flag is activated. In other words, you are treating the piece of example text as one long line of text.
Most of the time you are going to use the “g” flag only.
But it is good to understand there are other flags as well.
In the regexr online editor, you can find all the possible flags in the top right corner.
Now that you understand what regex is and what is the global flag, let’s see an example.
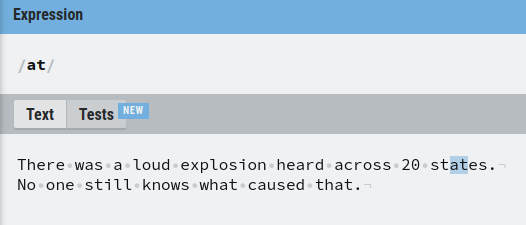
Let’s search for “at” in the piece of text:

As you can see, our regular expression found three matches of “at”.
Now, if you disable the “g” flag, it is only going to match the first occurrence of “at”.
Anyway, let’s switch the global flag back on.
So far using regex has been like using the good old CTRL+F.
However, the true power of the regular expressions shows up when we search for patterns instead of specific words.
To do this, we need to learn about the regex special characters that make pattern matching possible
Let’s start with the + charater.
The + Operator – Match One or More
Let’s search for character “s” in the example text.

This matches all “s” letters there are.
But what if you want to search for multiple “s” characters in a row?
In this case, you can use the + character after the letter “s”. This matches all the following “s” letters after the first one.

As a result, it now matches the double “s” in the text in addition to the singular “s”.
In short, the + operator matches one or more same characters in a row.
Next, let’s take a look at how optional matching works.
The ? Operator – Match Optional Characters
Optional matching is characterized by the question mark operator (?).
Optional matching means to match something that might follow.
For example, to match all letters “s” and every “s” followed by “t”, you can specify the letter “t” as an optional match using the question mark.
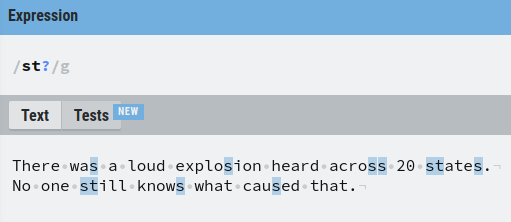
This matches:
- Each singular “s”
- Each combination of “st”.
Next up, let’s take a look at a special character that combines the + and ? characters.
The * Operator – Match Any Optional Characters
The star operator (*) means “match zero or more”.
Essentially, it is the combination of the + and the ? operators.
For example, let’s match with each letter “o” and any amount of letter “s” that follow.

This matches:
- All the singular “o” letters.
- All occurrences of “os”.
- All occurrences of “oss”.
As a matter of fact, this would match with “ossssssss” with any number of “s” letters as long as they are preceded by an “o”.
Next, let’s take a look at the wild card character.
The . Operator – Match Anything Except a New Line
In regex, the period is a special character that matches any singular character.
It acts as the wildcard.
The only character the period does not match is a line break.
For example, let’s match any character that comes before “at” in the text.

But how about matching with a dot then? The period (.) is a reserved special character, so it cannot be used.
This is where escaping is used.
The \ Operator – Escape a Special Character
If you are familiar with programming, you know what escaping means.
If not, escaping means to “invalidate” a reserved keyword or operator using a special character in front of its name.
As you saw in the previous example, the period character acts as a wildcard in regex. This means you cannot use it to match a dot in the text.

As you can see, /./g matches with each letter (and space) in the text, so it is not much of a help.
This is where escaping is useful.
In regex, you can escape any reserved character using a backslash (\).
Anything followed by a backslash is going to be converted into a normal text character.
To match dots using regex, escape the period character with (\.).

Now it matches all the dots in the text.
Let’s play with the example. To match any character that comes before a dot, add a period before the escaped period:
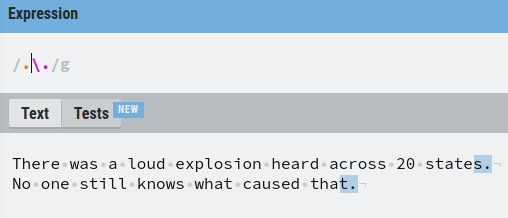
Now you understand how to match and escape characters in regex. Let’s move on to matching word characters using other special characters.
Match Different Types of Characters
You just learned how to use a backslash to escape a character.
However, the backslash has another important use case. Combining a backslash with some particular character forms an operator that can be used to match useful things.
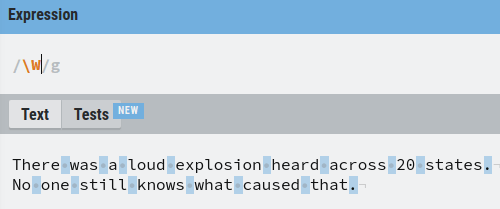
As an example, an important special character in regex is \w.
This matches all the word characters, that is, letters and digits but leaves out spaces.
For example, let’s match all the letters and digits in the text:

Another commonly used special operator is the space character \s that matches any type of white space there is in the text.
For example, let’s match all the spaces in the text.
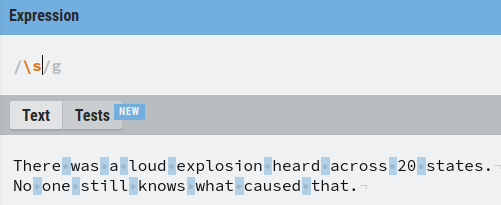
Of course, you can also match numeric characters only.
This happens via the \d operator.
For instance, let’s match all digits in the text:

This matches with “2” and “0”.
These are the very basic special character operators there are in regex.
Next, you are going to learn how to invert these special characters.
Invert Special Characters
To invert a special character in regex, capitalize it.
- \w matches any word character –> \W matches with any non-word character
- \s matches with any white space character –> \S matches with any non-whitespace character.
- \d matches with any digit –> \D matches any non-digit character.
Examples:


Next, let’s take a look at how to match words with a specific length.
{} – Match Specific Length
Let’s say you want to capture all the words that are longer than 2 characters long.
Now, you cannot use + or * with the \w character as it does not make sense.
Instead, use the curly braces {} by specifying how many characters to match.
There are three ways to use {}:
- {n}. Match n consecutive characters.
- {n,}. Match n character or more.
- {n,m}. Match between n and m in length.
Let’s examples of each.
Example 1. Match all sets of characters that are exactly 3 in length:

Example 2. Match consecutive strings that are longer than 3 characters:

Example 3. Match any set of characters that are between 3 and 5 characters in length:

Now that you know how to deal with quantities in regex, let’s talk about grouping.
[] – Groups and Ranges
In regex, you can use character grouping. This means you match with any character in the group.
One way to group characters is by using square brackets [].
For example, let’s match with any two letters where the last letter is “s” and the first letter is either “a” or “o”.

A really handy feature of using square brackets is you can specify a range. This lets you match any letter in the specified range.
To specify a range, use the dash with the following syntax. For example, [a-z] matches any letter from a to z.
For example, let’s match with any two-letter word that ends in “s” and starts with any character from a to z.
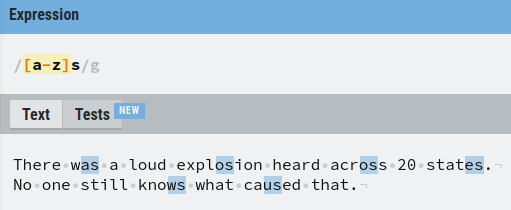
One thing you sometimes may want to do is to combine ranges.
This is also possible in regex.
For example, to find any two letters that end with “s” and start with any lowercase or uppercase letter, you can do:
/[a-zA-Z]s/g
Or if you want to match with any two letters that end with “s” and start with a number between 0 and 9, you can do:
/[0-9]s/g
Awesome.
Next, let’s take a look at another way to group characters in regex.
() Capturing Groups
In regex, capturing groups is a way to treat multiple characters as a single unit.
To create a capturing group, place the characters inside of the parenthesis.
For example, let’s match with words “The” or “the”, where the first letter is either lowercase t or uppercase T.
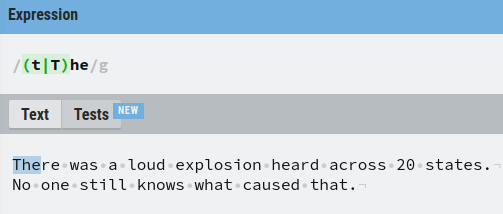
But why parenthesis? Let’s see what happens without them:
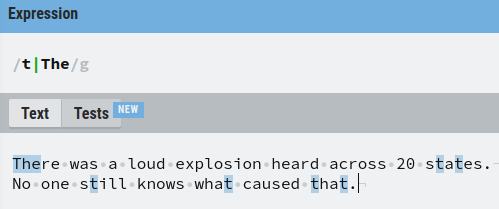
Now it matches with either any single character “t” or the word “The”.
This is the power of the capturing group. It treats the characters inside the parenthesis as a single unit.
Let’s see another example where we find any words that are 2-3 letters long and each letter in the word is either a,s,e,d.

As the last example of capturing, let’s match any words that repeat “os” two or three times in a row.

Here the “os” is not matched in the words “explosion” and “across”. This is because the “os” occurs only a single time. However, the “osososos” at the end has 3 x “os” so it gets matched.
Next up, let’s take a look at yet another special character, caret (^).
The ^ operator – Match the Beginning of a Line
The caret (^) character in regex means match with the beginning of the new line.
For example, let’s match with the letter “T” at the beginning of a text chapter.

Now, let’s see what happens when we try to match with the letter “N” at the beginning of the next line.

No matches!
But why is that? There is an “N” at the beginning of the second line.
This happens because our flag is set to “g” or “global”. We are treating the whole piece of text as a single line of text.
If you want to change this, you need to set the multiline flag in addition to the global flag.

Now the match is also made at the beginning of the second line.
However, it is easier to deal with the text as a single chunk of text, so we are going to disable the multiline flag for the rest of the guide.
Now that you know how the caret operator works in regex, let’s take a look at the next special character, the dollar sign ($).
$ End of Statement
To match the end of a statement with regex, use the dollar sign ($).
For instance, let’s match with a dot that ends the text chapter.

As you can see, this only matches the dot at the end of the second line. As mentioned before, this happens because we treat the text as a single line of text.
Awesome! Now you have learned most of the special characters you are ever going to use in regex.
Next, let’s take a look at how to really benefit from regex by learning about important concepts of lookahead and lookbehind.
Lookbehinds
In regex, a lookbehind means to match something preceded by something.
There are two types of lookbehinds:
- Positive lookbehind
- Negative lookbehind
Let’s take a look at what these do.
The (?<=) Operator – Positive Lookbehind
A positive look behind is specified by defining a group that starts with a question mark, followed by a less than sign and an equal sign, and then a set of characters.
- (?<=)
Here < means we are going to perform a look behind, and = means it is positive.
A positive lookbehind matches everything before the main expression without including it in the result.
For example, let’s match the first characters after “os” in the text.

This positive look behind does not include “os” in the matches. Instead, it checks if the matches are preceded by “os” before showing them.
This is super useful.
The (?<!) Operator – Negative Lookbehind
Another type of look behind is the negative look behind. This is basically the opposite of the positive lookbehind.
To create a negative look behind, create a group with a question mark followed by a less-than sign and an exclamation point.
- (?<!)
Here < means look behind and ! makes it negative.
As an example, let’s perform the exact same search as we did in the positive lookbehind, but let’s make it negative:

As you can see, the negative lookbehind matches everything except the first character after the word “os”. This is the exact opposite of the positive lookahead.
Now that you know what the lookbehinds do, let’s move on to very similar concepts, that is, lookaheads.
Lookaheads
In regex, a lookahead is similar to lookbehind.
A lookahead matches everything after the main expression without including it in the result.
To perform a lookahead, all you need to do is remove the less-than sign.
- (?=) is a positive lookahead.
- (?!) is a negative lookahead.
The (?=) Operator – Positive Lookahead
For example, let’s match with any singular character followed by “es” or “os”.
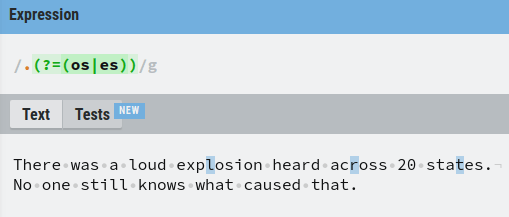
And as you guessed, a negative lookahead matches the exact opposite of what a positive lookahead does.
The (?!) Operator – Positive Lookahead
For example, let’s match everything except for the single characters that occur before “os” or “es”
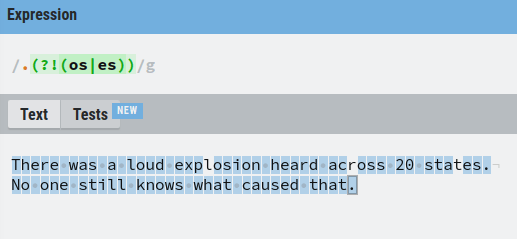
Now you have all the tools to understand a slightly more advanced example using regex. Also, you are going to learn a bunch of important things at the same, so keep on reading!
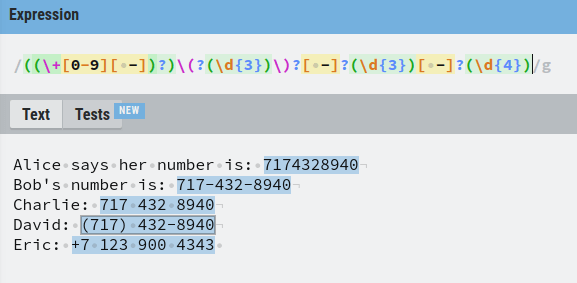
Find and Replace Phone Numbers Using Regex
Let’s say we have a text document that has differently formatted phone numbers.
Our task is to find those numbers and replace them by formatting them all in the same way.

The number that belongs to Alice is simple. Just 10 digits in a row.
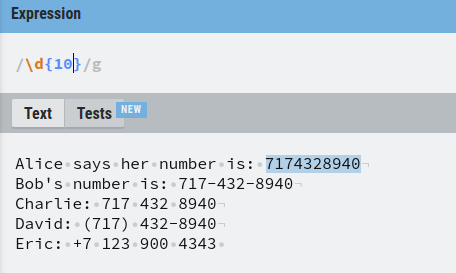
The number that belongs to Bob is a bit trickier because you need to group the regex into 5 parts:
- A group of three digits
- Dash
- A group of three digits
- Dash
- A group of four digits.
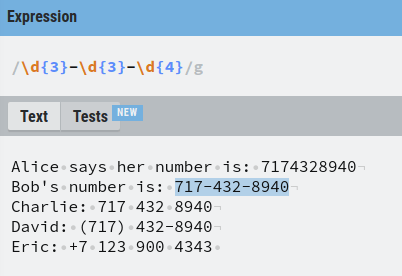
Now it matches Bob’s number.
But our goal was to match all the numbers at the same time. Now Alice’s number is no longer found.
To fix this, we need to restructure the regex again. Instead of assuming there is always a dash between the first two groups of numbers, let’s assume it is optional. As you now know, this can be done using the question mark.
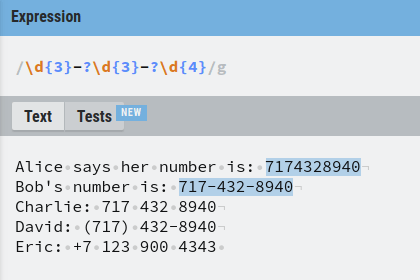
Good job.
Next up, there can also be numbers separated by space, such as Charlie’s number.
To take this into account, we must assume that the separator is either a white space or a dash. This can be done using a group with square brackets [] by placing a dash and a white space into it.
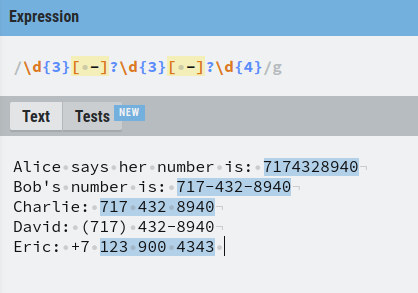
Now also Charlie’s number is matched by our regular expression.
Then there are those numbers where the first three digits are isolated by parenthesis and where the last two groups are separated by a dash.
To find these numbers, we need to add an optional parenthesis in front of the first three digits. But as you recall, parenthesis is a special character in regex, so you need to escape them using the backslash \.
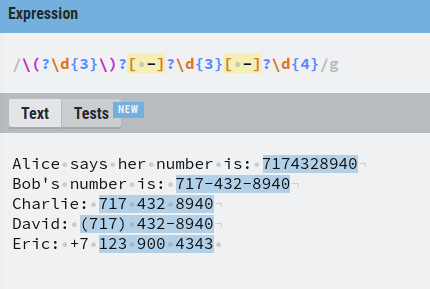
Awesome, now David’s number is also found.
Last but not least, a phone number might be formatted such that the country-specific number is in front of the number with a + sign.
To take this into account, we need to add an optional group of a + sign followed by a digit between 0-9.
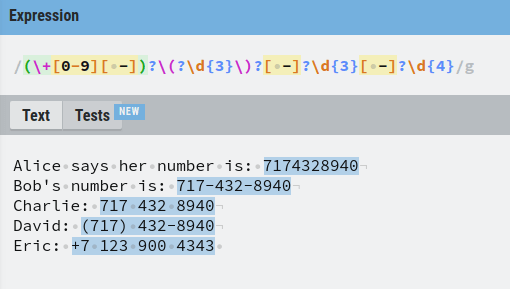
Now our regex finds every phone number there is on the list!
Next, let’s replace each number with a number such that each number is formatted in the same way.
Before we can do this, we need to capture each set of numbers by creating capturing groups for them. As you learned before, this happens by placing each set of digits into a set of parenthesis.
If you inspect the Details section of the editor, you can see that now each set of numbers in a phone number is grouped in the capture groups.
For example, let’s click the first phone number match and see the Details:
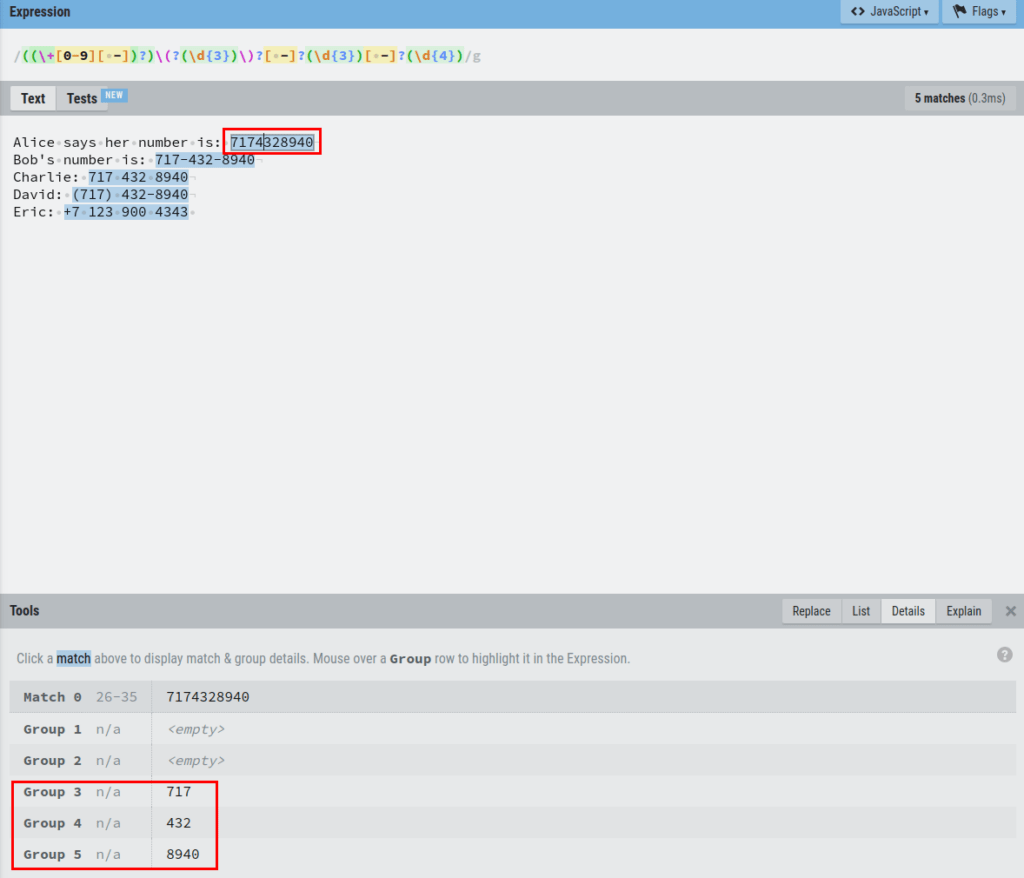
As you can see, the first phone number is grouped into three capture groups 3,4, and 5.
As another example, let’s click Eric’s number to see the details:
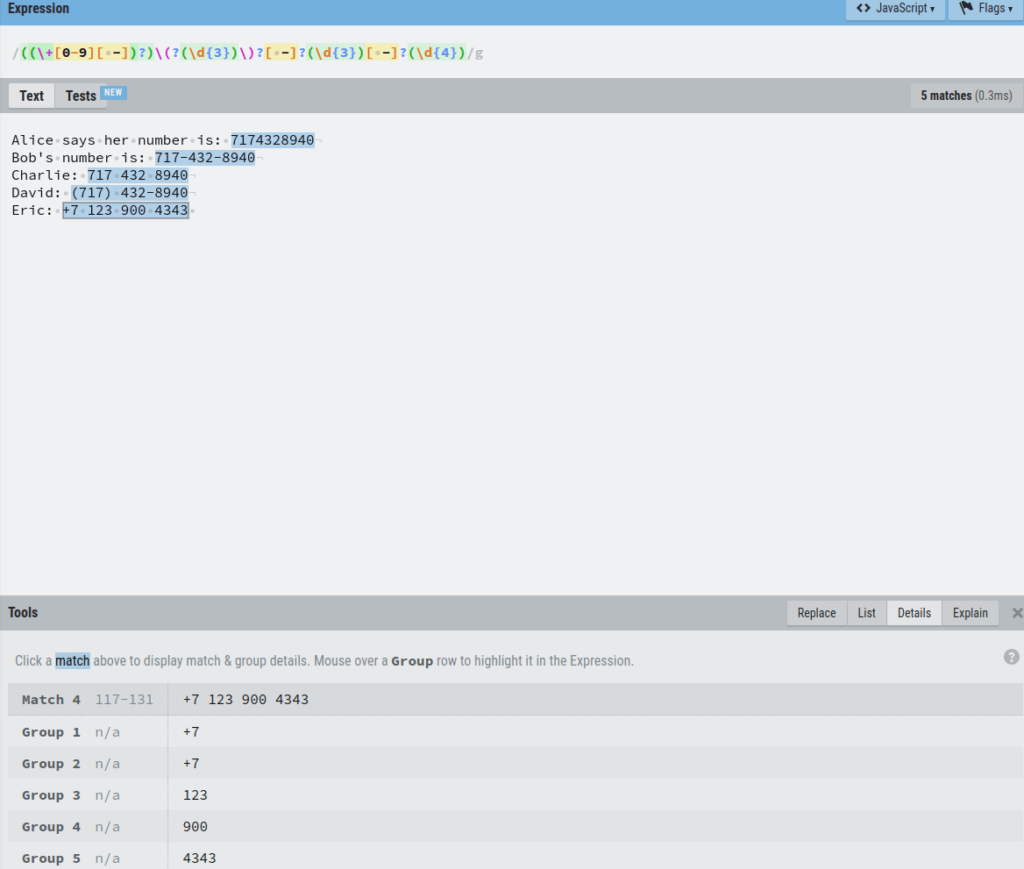
Here you can see that the number is split into groups 1, 2, 3, 4, and 5.
However, there is one problem.
The number +7 occurs twice, in group 1 and group 2.
This is not what we want.
It happens because the regex catches both the +7 with a space and without a space. Thus the 2 groups.
To get rid of this, you can specify the expression that captures the number with space as a non-capturing group.
To do this, use the ?: operator in front of the group:
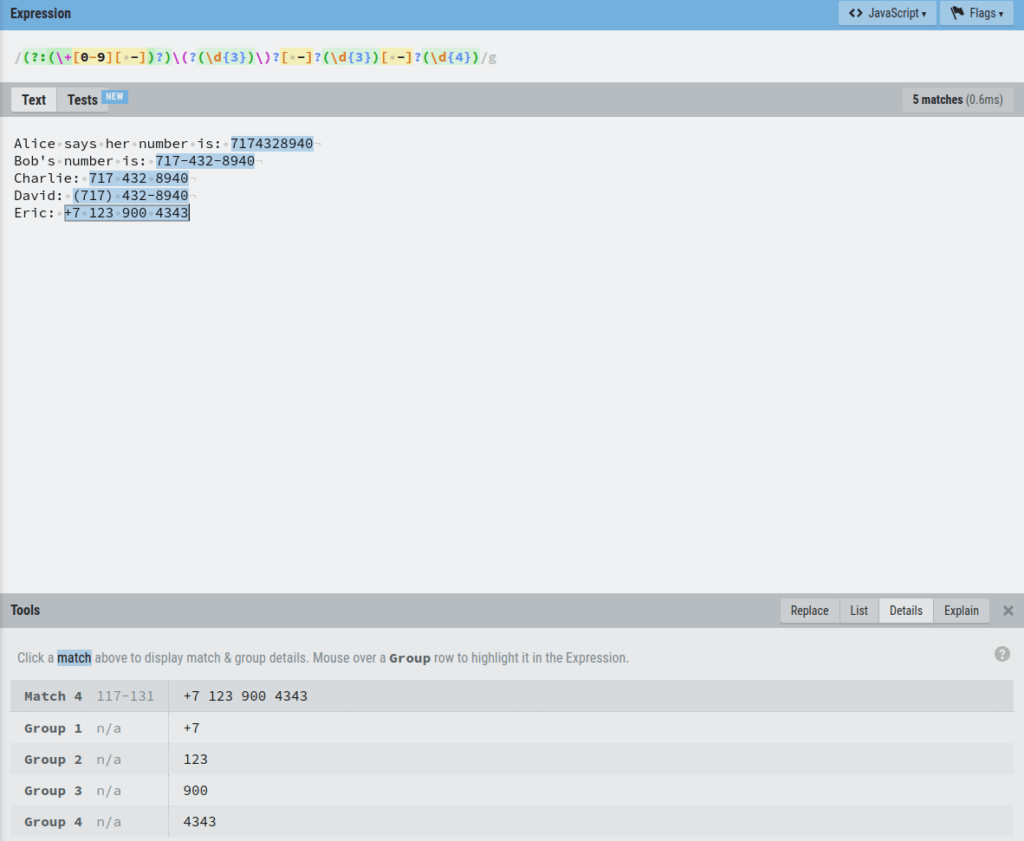
Now Eric’s number (and all the other numbers too) is nicely split into 4 groups.
Finally, we can use these four capture groups to replace the matched numbers with numbers that are formatted in the same way.
In regex, you can refer to each capture group with $n, where n is the number of the group.
To format the numbers, let’s open up the replace tab in the editor.
Let’s say we want to replace all the numbers with a number that is formatted like this:
+7 123-900-4343
And if there is no +7 in front of the number, then we leave it as:
123-900-4343
To do this, replace each phone number by referencing their capture group in the Replace section of the editor:
$1$2-$3-$4
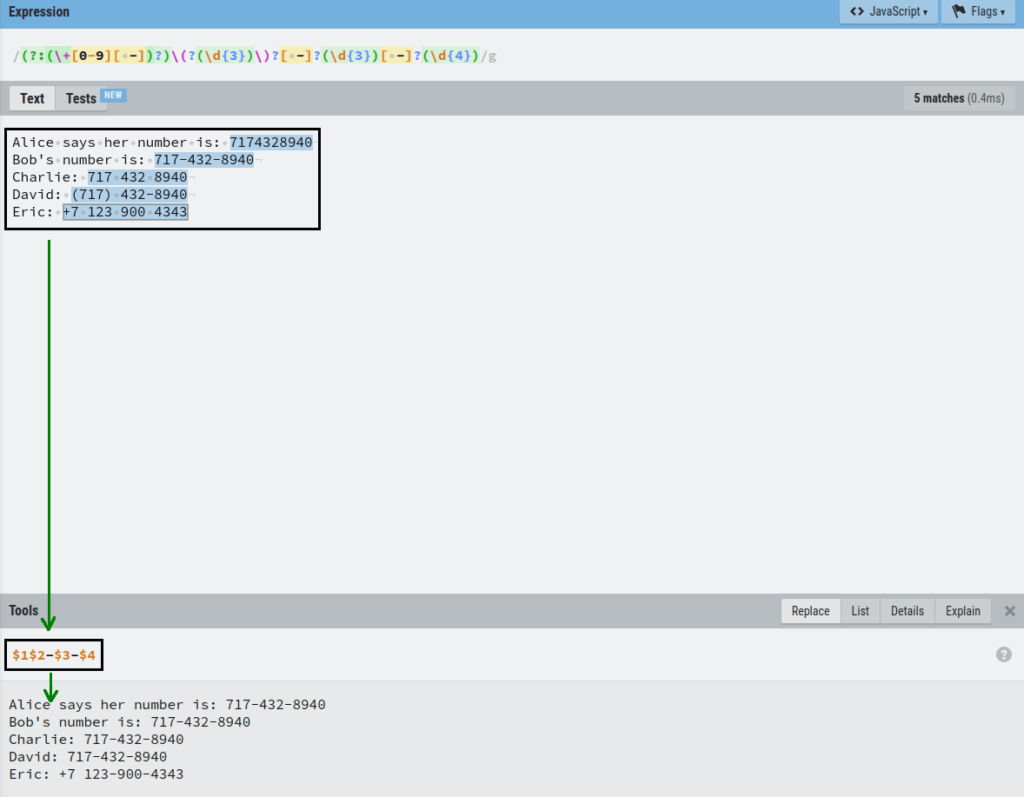
Amazing! Now all the numbers are replaced in the resulting piece of text and follow the same format.
This concludes our regex tutorial.
Conclusion
Today you learned how to use regex.
In short, regex is a commonly supported tool to match patterns in text documents.
You can use it to find and replace text that matches a specific pattern.
Most programming languages support regex. This means you can use regex in your coding projects to automate a lot of manual work when it comes to text processing.
Thanks for reading.
Happy pattern-matching!