To calculate the standard error of the mean (SEM) in Python, use scipy library’s sem() function.
For instance, let’s calculate the SEM for a group of numbers:
from scipy.stats import sem # Create a dataset data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4] # Calculate the standard error of mean s = sem(data) print(s)
Output:
13.172598656753378
If you do not have scipy installed, run:
pip install scipy
That was the quick answer. But make sure to read along to learn about the standard error and how to implement the function yourself.
What Is Standard Error of Mean (SEM)
The standard error of the mean (SEM) is an estimate of the standard deviation.
The SEM is used to measure how close sample means are likely to be to the true population mean. This gives a good indication as to where a given sample actually lies in relation to its corresponding population.
The standard error of the mean follows the following formula:
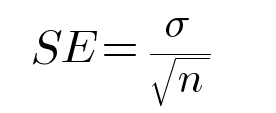
Where σ is the standard deviation and n is the number of samples.
Implementing Standard Error of Mean in Python
To write a function that calculates the standard error of the mean in Python, you first need to implement a function that calculates the standard deviation of the data.
What Is the Standard Deviation?
Standard deviation is a measure of how far numbers lie from the average.
For example, if we look at a group of men we find that most of them are between 5’8” and 6’2” tall. Those who lie outside this range make up only a small percentage of the group. The standard deviation identifies the percentage by which the numbers tend to vary from the average.
The standard deviation follows the formula:
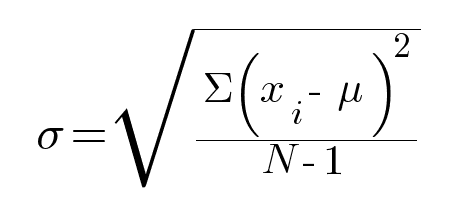
Where:
 = sample standard deviation
= sample standard deviation
 = the size of the population
= the size of the population = each value from the population
= each value from the population = the sample mean (average)
= the sample mean (average)
Calculating Standard Deviation in Python
Assuming you do not use a built-in standard deviation function, you need to implement the above formula as a Python function to calculate the standard deviation.
Here is the implementation of standard deviation in Python:
from math import sqrt
def stddev(data):
N = len(data)
mu = float(sum(data) / len(data))
s = [(x_i - mu) ** 2 for x_i in data]
return sqrt(float(sum(s) / (N - 1)))
The Standard Error of Mean in Python
Now that you have set up a function to calculate the standard deviation, you can write the function that calculates the standard error of the mean.
Here is the code:
def sem(data):
return stddev(data) / sqrt(len(data))
Now you can use this function.
For example:
data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4] sem_data = sem(data) print(sem_data)
Output:
13.172598656753378
To verify that this really is the SEM, use a built-in SEM function to double-check. Let’s use the one you already saw in the introduction:
from scipy.stats import sem # Create a dataset data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4] # Calculate the standard error of mean s = sem(data) print(s)
As a result, you get the same output as the custom implementation yielded.
13.172598656753378
This completes our example of building the functionality for calculating the standard error of the mean in Python.
Here is the full code used in this example for your convenience:
from math import sqrt
def stddev(data):
N = len(data)
mu = float(sum(data) / len(data))
s = [(x_i - mu) ** 2 for x_i in data]
return sqrt(float(sum(s) / (N - 1)))
def sem(data):
return stddev(data) / sqrt(len(data))
data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4]
sem_data = sem(data)
print(sem_data)
This is the hard way to obtain the standard error of the mean in Python.
Usually, when you have a common problem, you should rely on using existing functionality as much as possible.
Let’s next take a look at the two ways to find the standard error of the mean in Python using built-in functionality.
SEM Using Python Libraries
While it is possible to implement SEM function yourself, using a Python library such as NumPy or SciPy has several advantages.
Libraries are optimized for fast computation, so using a library can save you time and effort in writing and optimizing your own code.
The standard error of the mean involves several mathematical operations, including the calculation of the sample standard deviation and the square root of the sample size, so using a pre-built library function can save you a significant amount of time and effort.
Libraries also provide convenience by providing pre-built functions for common statistical calculations, including the standard error of the mean.
This means that you do not have to worry about the details of the implementation and can easily integrate the calculation into your code.
1. Standard Error of Mean Using Scipy
You have seen this approach already twice in this guide.
The scipy module comes with a built-in sem() function. This directly calculates the standard mean of error for a given dataset.
For instance:
from scipy.stats import sem # Create a dataset data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4] # Calculate the standard error of mean s = sem(data) print(s)
Output:
13.172598656753378
2. Standard Error of Mean Using Numpy
You can also use NumPy module to calculate the standard error of the mean in Python.
However, there is no dedicated sem() function in numpy. But there is a function called std() that calculates the standard deviation.
So, to calculate the SEM with NumPy, calculate the standard deviation and divide it by the square root of the data size.
For example:
import numpy as np data = [19, 2, 12, 3, 100, 2, 3, 2, 111, 82, 4] sem_data = np.std(data, ddof=1) / np.sqrt(np.size(data)) print(sem_data)
Output:
13.172598656753378
Conclusion
Today you learned how to calculate the standard error of the mean in Python.
To recap, the standard error of the mean is an estimate of the standard deviation of all samples that could be drawn from a particular population.
To calculate the SEM in Python, you can use scipy‘s sem() function.
Another way to calculate SEM in Python is by using the NumPy module. But there is no direct sem() function there. Thus you need to use the standard deviation and the equation of SEM.
The laborious approach to find the SEM is to implement the sem() function yourself. To do this, you need to implement the functionality to calculate the standard deviation first. Then the rest is simple.
Thanks for reading. Happy coding!